


The ALPSP panel for this discussion on AI and the impact it is having within academic publishing was made up of Nicola Davies, IOP Publishing (Co-chair), Helene Stewart, Clarivate (Co-Chair), Meurig Gallagher, University of Birmingham (Speaker), Matt Hodgkinson, UKRIO (Speaker) and Jennifer Wright, CUP RI Manager (Speaker).
It was fascinating to see how the conversation around AI has moved on within a few months regarding this technological advancement. Institutions, publishers and journal stakeholders all have a concept of AI and are developing policies and guidance about how we should be using it and are underpinning the “what for?”.
Many of us by now will have tried asking a Large Language Model (LLM) to write a paragraph or create an image using Artificial Intelligence. It’s brilliant to watch how quickly tasks can be created, large blocks of text are generated at an immense speed, and right before us we see how quickly human intelligence can be mimicked. This notion was highlighted in Meurig Gallagher’s presentation; that essentially AI is trying to act as human as possible using the instructions it has been provided with. However, when these tools are posed with mathematical equations it does not have the knowledge to apply the learning and therefore can spectacularly fail! These “gaps” therefore build into the guidance stakeholders need to be aware of when creating policy around AI – it cannot be relied upon solely to do the work. Matt Hodgkinson developed this further and shared many caveats that researchers and general users might come up against when using chatbots:
- Many LLMs are unvalidated for scholarly uses.
- References should be fact-checked as they can be falsified, therefore it is important to check sources and supporting literature.
- The quality of evidence is not assured.
- Outputs may be based on using out-of-date information based on “old” training material.
The ominous but noteworthy warning was circulated that “if you are not an expert, you will be fooled by fluent but incorrect outputs”. Therefore, all of us involved in scholarly publishing need to be mindful of these contributions and check author statements within articles to assess whether an LLM has been used. Of course, one of the largest threats we are witnessing is the output of paper mills and their use of AI could lead to the tool’s collapse as its knowledge bank is infiltrated with “fake” data, which if left undetected will pollute the pool where the data is extracted from.
Nonetheless the principles of Research Integrity can be applied to the use of AI-generated content and Matt shared this slide to disclose how these principles are applied:
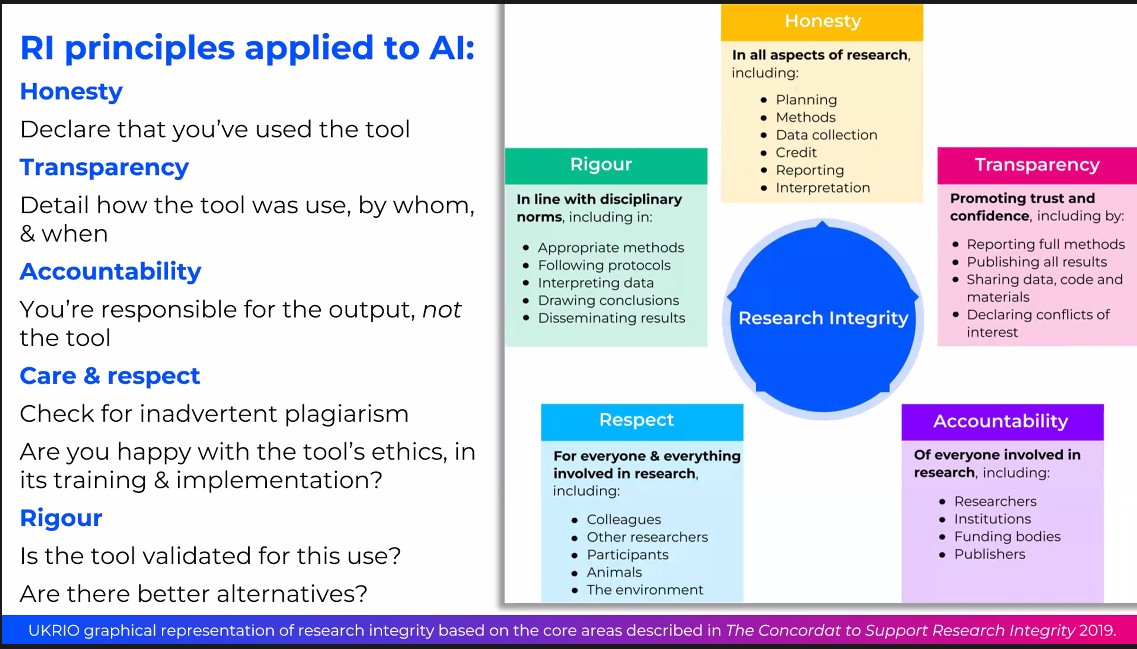
UKRIO presentation at ALPSP 2024
Dr Jennifer Wright from Cambridge University Press shared with the audience how to implement transparency which is really the crux of what many VEOs are looking at. It was suggested that AI declarations should be included within image captions, acknowledgements, and methodologies if applicable and the details that should be shared include the type of model that was used, eg: CHATGPT, and how and when it was accessed. It is also important to include any additional COI statements because of the use of the model. Looking forwards, Dr Wright elaborated on future considerations and posed some important questions around reporting standards: What will the impact be of AI on the scholarly record? How could/should/will research and publication practices change? How will concepts such as retractions be enforced? Can a bot retrain itself?
The challenges are still clearly evident with AI. However the more we progress and understand how it can be used, trust markers can be identified to validate the outputs. As long as scholars use and do not abuse the tech, we could watch something incredible unfold!